Minimax
The minimax algorithm is attributed to John von Neumann (1928, Zur Theorie der Gesellschaftsspiele), but its key features were described earlier by Émile Borel (1921, La théorie du jeu et les équations intégrales à noyau symétrique). It has also been sugested that Charles Babbage may have known about the algorithm. Irregardless of who formalised it, anyone who has ever played Draughts, Chess, Go, or countless other games, has used it. At any point in the game you choose your next move by thinking several ahead, and considering what you and your opponent will do to maximise their respective chances of winning. In the formal version ‘several ahead’ means all the way to the very end, where one of you has won.
Minimax is an algorithm of game theory (a term invented by von Neumann with Morgenstern), which formalises how to act when you are in competition with others (If you want to know more then The Joy of Game Theory by Presh Talwalkar is a friendly introduction). The basic version introduced here is for finding the optimal move in zero sum games that are turn based with two players where everything is deterministic and observable, and you have enough computation/memory to exhaust the search tree. To define these terms:
- zero sum: There are n points to be won and they are distributed between the players at the end of the game. In other words, there is no possibility of cooperation, and one players fortune is anther’s loss. Any game where one player wins and the other loses satisfies this; a draw is half the points to each player.
- turn based: Players take turns to make a move.
- two player: There are two players!
- deterministic: No dice. The consequence of any action is known, exactly.
- observable: No secrets, so both players know everything.
- search tree: This is every possible state the game can be in, and the transitions (moves) between them made by the players.
The minimax algorithm is solving the Nash equilibrium (Its discovery is the subject of the film A Beautiful Mind (2001)) for games with the above properties. Note that many of the above properties can be relaxed with more sophisticated versions. Even when it can’t approximations are used: Alpha Go used minimax to beat homosapiens at Go, but never could have held the entire search tree of Go in memory; that would be more states than there are atoms in the universe… even after you bulked up by replacing every atom with a copy of the universe. Instead, it used machine learning to estimate what the probability of winning from any state was, so it didn’t have to search to the end.
Noughts and crosses
You should know this game, as everybody plays it as a kid until they master it and it becomes boring. But in case your childhood is a little fuzzy around the edges, here is a reminder. Two players take turns to place symbols on a 3x3 grid. First one to make a line (horizontal, vertical, or diagonal) of three of their symbol wins. Tradition is that the crosses (\( x \)) go first, the noughts (\( o \)) second.
Here is an example game (rendered using ascii art, with only the vertical lines!):
| | | | | |x | |x |x|x o|x|x o|x|x
|x| -> |x|o -> |x|o -> |x|o -> |x|o -> |x|o -> |x|o
| | | | | | o| | o| | o| | o|x|
\( x \) ultimately wins with a vertical line. As for when \( o \) lost, they did so with their very first move, even though it took \( x \) a few moves to force the win.
Minimax explanation
Minimax is best understood by starting at the end of a game. Imagine the board looks like this:
o|x|x
|x|o
o|x|
The game has ended, and \( x \) has won. Lets say that the value is \( +1 \) when \( x \) wins, \( -1 \) when \( o \) wins, and \( 0 \) for a draw. So this state (of the board) has a score of \( +1 \).
Key to minimax is the realisation that if we can assign a score to the end states then we can assign a score to any other state by assuming the players always play the best move available. For \( x \) that means the move that maximises the score, for \( o \) that means the move that minimises the score.
Lets go back a move:
o|x|x
|x|o
o| |
How do we assign a score? It is the turn of \( x \) and they have three choices:
o|x|x o|x|x o|x|x
x|x|o |x|o |x|o
o| | o|x| o| |x
If we assume the score is defined for each of these states then naturally \( x \) will play the move associated with ending in the highest scoring state.
We know the score for the middle state is \( +1 \), as it is a winning state. What about the other two? The score of the left and right states can be calculated in the exact same way as for this state, the one difference being it will then be the turn of \( o \), who will want to minimise the score.
The left state has two choices for \( o \):
o|x|x o|x|x
x|x|o x|x|o
o|o| o| |o
which will be immediately followed by \( x \) taking the only move it has left and ending the game. On the left this is a draw (score=\( 0 \)), and on the right a win for \( x \) (score=\( +1 \)). \( o \) wants to minimise so it will choose the left choice - a draw is preferable to a loss. So the left state scores \( 0 \) when \( x \) looks at it, because \( x \) assumes \( o \) will do the best they can. The same argument holds for the right choice. So when \( x \) is taking its move it will always choose the middle option, because it has the highest score, corresponding to victory.
This pattern repeats. Going right back to the start of the game \( x \) will consider every possible game that can be played, all the way to the end. And by assuming that it always takes the best move, and the opposition always takes the best move avaliable to it (worst move for \( x \) because it’s a zero sum game), it can calculate the score for every state as the minimum or maximum of the next move, depending on whose turn it is. The name of the algorithm, minimax, comes from this repeating pattern of selecting the minimum and maximum score.
Here are some further explanations:
- Terrible explanation. Included in this list so I can tell you not to read it.
- Clear but theoretical.
- An article on how AlphaGo works.
Board State
To represent board states we’re going to use a tuple of tuples, so that you may index them with \( [row][column] \), where \( [0][0] \) is the top left and \( [2][2] \) the bottom right.
def print_state(state):
"""Prints the state."""
for i in range(len(state)):
print(state[i][0] + "|" + state[i][1] + "|" + state[i][2])
print()
# **************************************************************** (1 mark)
# Code to test the above; output should be:
# | |
# | |
# | |
#
# o|x|x
# |x|o
# o|x|
#
# o|o|o
# x|x|x
# | |
print_state(((" ", " ", " "), (" ", " ", " "), (" ", " ", " ")))
print() # This adds a newline, so the outputs are not vertically next to each other
print_state((("o", "x", "x"), (" ", "x", "o"), ("o", "x", " ")))
print()
print_state((("o", "o", "o"), ("x", "x", "x"), (" ", " ", " ")))
| |
| |
| |
o|x|x
|x|o
o|x|
o|o|o
x|x|x
| |
Scoring
We need to be able to detect when a winning move has been played, and assign a score to it.
- If \( x \) has won return 1
- If \( o \) has won return -1
- If it is a draw return 0
- If nobody has won, and moves can still be played, return None
def score_end(state):
"""Scores the game state if the game has ended, otherwise returns None."""
# -----------------------------------------------#
# Check to see if a winning move has been played
# -----------------------------------------------#
# First check to detect rows
for row in state:
row_test = "".join(row)
if "xxx" in row_test:
return 1
if "ooo" in row_test:
return -1
# Second check to detect columns
for i in range(len(state)):
col_test = state[0][i] + state[1][i] + state[2][i]
if "xxx" in col_test:
return 1
if "ooo" in col_test:
return -1
# Third check to detect diagonals
test_1st_diagonal = state[0][0] + state[1][1] + state[2][2]
test_2nd_diagonal = state[2][0] + state[1][1] + state[0][2]
if "xxx" in test_1st_diagonal:
return 1
if "xxx" in test_2nd_diagonal:
return 1
if "ooo" in test_1st_diagonal:
return -1
if "ooo" in test_2nd_diagonal:
return -1
# Final check to see if the game has started or finished
unpacked = []
for i in range(len(state)):
for j in range(len(state)):
unpacked.append(state[i][j])
unpacked_list = "".join(unpacked)
# Moves can still be made
if " " in unpacked_list:
return None
# Draw Condition
else:
return 0
# **************************************************************** (3 marks)
# Code to test the above function...
print(
"Expected: None; Obtained:",
score_end(((" ", " ", " "), (" ", " ", " "), (" ", " ", " "))),
)
print(
"Expected: 1; Obtained:",
score_end((("o", " ", "o"), ("x", "x", "x"), (" ", " ", " "))),
)
print(
"Expected: 1; Obtained:",
score_end((("o", "x", "x"), (" ", "x", "o"), ("o", "x", " "))),
)
print(
"Expected: 1; Obtained:",
score_end((("o", "x", "x"), (" ", "x", "o"), ("x", "o", " "))),
)
print(
"Expected: -1; Obtained:",
score_end((("o", "x", "x"), (" ", "x", "o"), ("o", "o", "o"))),
)
print(
"Expected: -1; Obtained:",
score_end((("o", "x", " "), ("o", "x", " "), ("o", " ", "x"))),
)
print(
"Expected: -1; Obtained:",
score_end(((" ", "x", "o"), (" ", "o", "x"), ("o", " ", "x"))),
)
print(
"Expected: 0; Obtained:",
score_end((("o", "x", "o"), ("x", "x", "o"), ("o", "o", "x"))),
)
Expected: None; Obtained: None
Expected: 1; Obtained: 1
Expected: 1; Obtained: 1
Expected: 1; Obtained: 1
Expected: -1; Obtained: -1
Expected: -1; Obtained: -1
Expected: -1; Obtained: -1
Expected: 0; Obtained: 0
Playing a Move
Given a state, as described above, and a move, e.g. ‘place a \( x \) at row 2, column 1’ we need a function that will return a new state, with the move having been played.
Input:
- State before the move.
- Row to modify.
- Column to modify.
- What to place, \( x \) or \( o \).
def play(state, row, col, mark):
"""Returns a new state after the given move has been played."""
lst_state = [list(i) for i in state]
lst_state[row][col] = mark
state = tuple([tuple(i) for i in lst_state])
# **************************************************************** (2 marks)
return state
# Code to test the above function - it should play the game given in the 'noughts and crosses' section above...
start = ((" ", " ", " "), (" ", " ", " "), (" ", " ", " "))
move1 = play(start, 1, 1, "x")
move2 = play(move1, 1, 2, "o")
move3 = play(move2, 0, 2, "x")
move4 = play(move3, 2, 0, "o")
move5 = play(move4, 0, 1, "x")
move6 = play(move5, 0, 0, "o")
move7 = play(move6, 2, 1, "x")
print_state(start)
print("")
print_state(move1)
print("")
print_state(move2)
print("")
print_state(move3)
print("")
print_state(move4)
print("")
print_state(move5)
print("")
print_state(move6)
print("")
print_state(move7)
# The assert statement throws an error if what it is testing is not true.
# The below assert statements confirm that the output of play is nested tuples.
# 'is' when applied to core types (such as tuple) ensures exact equivalence.
assert type(move7) is tuple
assert type(move7[0]) is tuple
assert type(move7[1]) is tuple
assert type(move7[2]) is tuple
| |
| |
| |
| |
|x|
| |
| |
|x|o
| |
| |x
|x|o
| |
| |x
|x|o
o| |
|x|x
|x|o
o| |
o|x|x
|x|o
o| |
o|x|x
|x|o
o|x|
Finding Possible Moves
Given a state we need to know all of the possible moves that the current player can make, that is, a list containing the coordinates of all empty places.
import numpy as np
def moves(state):
"""Returns the list of moves that are avaliable from the current state."""
lst_state = np.array(state)
state_mask = np.where(lst_state == " ")
coordinates = list(zip(state_mask[0], state_mask[1]))
return coordinates
# **************************************************************** (1 mark)
# Testing the above function. Note that a set is another Python data type;
# it's value here is it doesn't care about order when making comparisons, so if you
# output the list of moves in a different order it still does the right thing...
moves1 = moves(((" ", " ", " "), (" ", " ", " "), (" ", " ", " ")))
assert set(moves1) == set(
[(0, 0), (0, 1), (0, 2), (1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)]
)
moves2 = moves((("o", " ", "o"), ("x", "x", "x"), (" ", " ", " ")))
assert set(moves2) == set([(0, 1), (2, 0), (2, 1), (2, 2)])
moves3 = moves((("o", "x", "o"), ("x", "x", "o"), ("o", "o", "x")))
assert moves3 == []
Minimax
Now to implement the minimax algorithm; finish the below function such that:
Input:
- A game state.
- Whose turn it is, either \( x \) or \( o \).
Output:
- The estimated score of the game.
- None if the game has ended, or a tuple of (row, column), the move the player is to take.
def score(state, player):
"""Recursive scorer implementing the minimax algorithm."""
def minimax(state, maximise):
"""If the player is x we want to find the best move for o and x wants to play that move.
If the player is o we want to find the best move for x and o wants to play that move."""
# Output for the base cases of recursion
if score_end(state) == 1:
return 1
elif score_end(state) == -1:
return -1
elif score_end(state) == 0:
return 0
if maximise == True:
best_score = -10
possible_moves = moves(state)
# Loop over the moves
for (row, column) in possible_moves:
state = play(state, row, column, "x")
score = minimax(state, False)
# Undo the move
state = play(state, row, column, " ")
best_score = max(score, best_score)
return best_score
# Minimise
elif maximise == False:
best_score = 10
possible_moves = moves(state)
for (row, column) in possible_moves:
state = play(state, row, column, "o")
score = minimax(state, True)
state = play(state, row, column, " ")
best_score = min(score, best_score)
return best_score
"""Simulate the games."""
if player == "x":
best_score = -10
best_move = None
possible_moves = moves(state)
for (row, column) in possible_moves:
state = play(state, row, column, "x")
score = minimax(state, False)
state = play(state, row, column, " ")
if score > best_score:
best_score = score
best_move = row, column
elif player == "o":
best_score = 10
best_move = None
possible_moves = moves(state)
for (row, column) in possible_moves:
state = play(state, row, column, "o")
score = minimax(state, True)
state = play(state, row, column, " ")
if score < best_score:
best_score = score
best_move = row, column
return best_score, best_move
print(
"Expected = 0; Obtained:",
score(((" ", " ", " "), (" ", " ", " "), (" ", " ", " ")), "x")[0],
)
print(
"Expected = 1; Obtained:",
score(((" ", " ", " "), (" ", "x", "o"), (" ", " ", " ")), "x")[0],
)
print(
"Expected = 1; Obtained:",
score((("x", " ", " "), (" ", "x", "o"), (" ", " ", " ")), "o")[0],
)
print(
"Expected = -1; Obtained:",
score((("o", " ", " "), ("x", " ", " "), ("o", " ", " ")), "o")[0],
)
Expected = 0; Obtained: 0
Expected = 1; Obtained: 1
Expected = 1; Obtained: 1
Expected = -1; Obtained: -1
A Perfect Game
%%timeit
def perfect_game(state, player):
def switch_player(player):
"""Switches the players for before and after the simulation."""
if player == "x":
return "o"
if player == "o":
return "x"
while score_end(state) == None:
_, best_coordinate = score(state, player)
state = play(state, best_coordinate[0], best_coordinate[1], player)
print_state(state)
player = switch_player(player)
return score_end(state)
state = ((" ", " ", " "), (" ", " ", " "), (" ", " ", " "))
player = "o"
result = perfect_game(state, player)
result
o| |
| |
| |
o| |
|x|
| |
o|o|
|x|
| |
o|o|x
|x|
| |
o|o|x
|x|
o| |
o|o|x
x|x|
o| |
o|o|x
x|x|o
o| |
o|o|x
x|x|o
o|x|
o|o|x
x|x|o
o|x|o
0
8.43 s ± 95.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Alpha-Beta Pruning
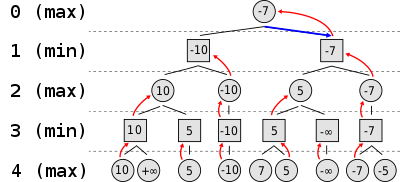
Alpha–beta pruning is a search algorithm that seeks to decrease the number of nodes that are evaluated by the minimax algorithm in its search tree. It is an adversarial search algorithm used commonly for machine playing of two-player games (Tic-tac-toe, Chess, Go, etc.). It stops evaluating a move when at least one possibility has been found that proves the move to be worse than a previously examined move. Such moves need not be evaluated further. When applied to a standard minimax tree, it returns the same move as minimax would, but prunes away branches that cannot possibly influence the final decision.
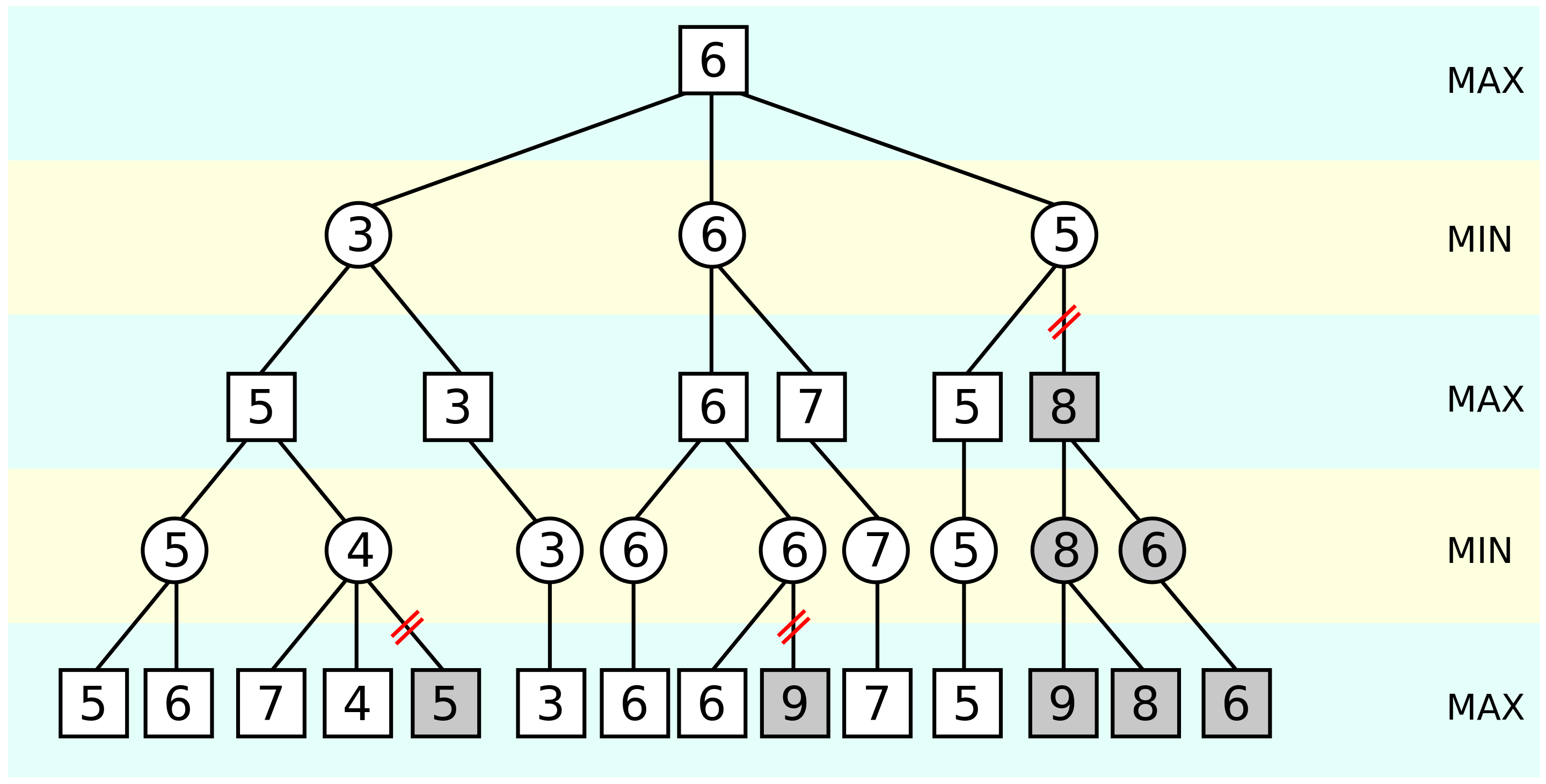
A speed up from 8s to 0.1s!
import functools
def score_alpha_beta(state, player):
"""Recursive scorer implementing the minimax algorithm."""
@functools.lru_cache(maxsize=100000)
def minimax(state, maximise, alpha=-10, beta=10):
"""If the player is x we want to find the best move for o and x wants to play that move.
If the player is o we want to find the best move for x and o wants to play that move.
Added alpha beta pruning and caching."""
# Output for the base cases of recursion
if score_end(state) == 1:
return 1
elif score_end(state) == -1:
return -1
elif score_end(state) == 0:
return 0
if maximise == True:
best_score = -10
possible_moves = moves(state)
# Loop over the moves
for (row, column) in possible_moves:
state = play(state, row, column, "x")
score = minimax(state, False, alpha, beta)
# Undo the move
state = play(state, row, column, " ")
best_score = max(score, best_score)
# Alpha beta pruning
alpha = max(alpha, score)
if beta <= alpha:
break
return best_score
# Minimise
elif maximise == False:
best_score = 10
possible_moves = moves(state)
for (row, column) in possible_moves:
state = play(state, row, column, "o")
score = minimax(state, True, alpha, beta)
state = play(state, row, column, " ")
best_score = min(score, best_score)
beta = min(beta, score)
if beta <= alpha:
break
return best_score
"""Simulate the games."""
if player == "x":
best_score = -10
best_move = None
possible_moves = moves(state)
for (row, column) in possible_moves:
state = play(state, row, column, "x")
score = minimax(state, False)
state = play(state, row, column, " ")
if score > best_score:
best_score = score
best_move = row, column
elif player == "o":
best_score = 10
best_move = None
possible_moves = moves(state)
for (row, column) in possible_moves:
state = play(state, row, column, "o")
score = minimax(state, True)
state = play(state, row, column, " ")
if score < best_score:
best_score = score
best_move = row, column
return best_score, best_move
print(
"Expected = 0; Obtained:",
score_alpha_beta(((" ", " ", " "), (" ", " ", " "), (" ", " ", " ")), "x")[0],
)
print(
"Expected = 1; Obtained:",
score_alpha_beta(((" ", " ", " "), (" ", "x", "o"), (" ", " ", " ")), "x")[0],
)
print(
"Expected = 1; Obtained:",
score_alpha_beta((("x", " ", " "), (" ", "x", "o"), (" ", " ", " ")), "o")[0],
)
print(
"Expected = -1; Obtained:",
score_alpha_beta((("o", " ", " "), ("x", " ", " "), ("o", " ", " ")), "o")[0],
)
Expected = 0; Obtained: 0
Expected = 1; Obtained: 1
Expected = 1; Obtained: 1
Expected = -1; Obtained: -1
%%timeit
def perfect_game(state, player):
def switch_player(player):
"""Switches the players for before and after the simulation."""
if player == "x":
return "o"
if player == "o":
return "x"
while score_end(state) == None:
_, best_coordinate = score_alpha_beta(state, player)
state = play(state, best_coordinate[0], best_coordinate[1], player)
print_state(state)
player = switch_player(player)
return score_end(state)
state = ((" ", " ", " "), (" ", " ", " "), (" ", " ", " "))
player = "o"
result = perfect_game(state, player)
result
o| |
| |
| |
o| |
|x|
| |
o|o|
|x|
| |
o|o|x
|x|
| |
o|o|x
|x|
o| |
o|o|x
x|x|
o| |
o|o|x
x|x|o
o| |
o|o|x
x|x|o
o|x|
o|o|x
x|x|o
o|x|o
0
166 ms ± 414 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)